Crowd-Sourcing Data
We partner with taxi drivers across Latin America to harvest rare, out-of-distribution driving footage — the raw material that makes truly robust autonomous driving possible.
We partner with taxi drivers across Latin America to harvest rare, out-of-distribution driving footage — the raw material that makes truly robust autonomous driving possible.
We onboard taxi drivers in Lima, Cusco, Cajamarca and expanding cities, equipping their vehicles with dashcams that capture continuous video, GPS and IMU data.
Footage is automatically uploaded, validated for quality, and ingested into our cloud data pipeline — processing thousands of hours of driving video per week.
Every clip is annotated with object classes, GPS coordinates, and scenario tags, then versioned and released to our model training pipeline and research partners.
22+ Lima districts, mountain routes in Cusco, rural roads in Cajamarca — environments that benchmark models have never seen before.
All footage is anonymised at source. Driver faces and licence plates are blurred before any data leaves the vehicle.
Video is paired with high-precision GPS and IMU readings, enabling 3D scene reconstruction and simulation environment generation.
The same partner-driver model is being rolled out to New York City, Miami, and Boston — expanding coverage to regulated, dense urban environments.
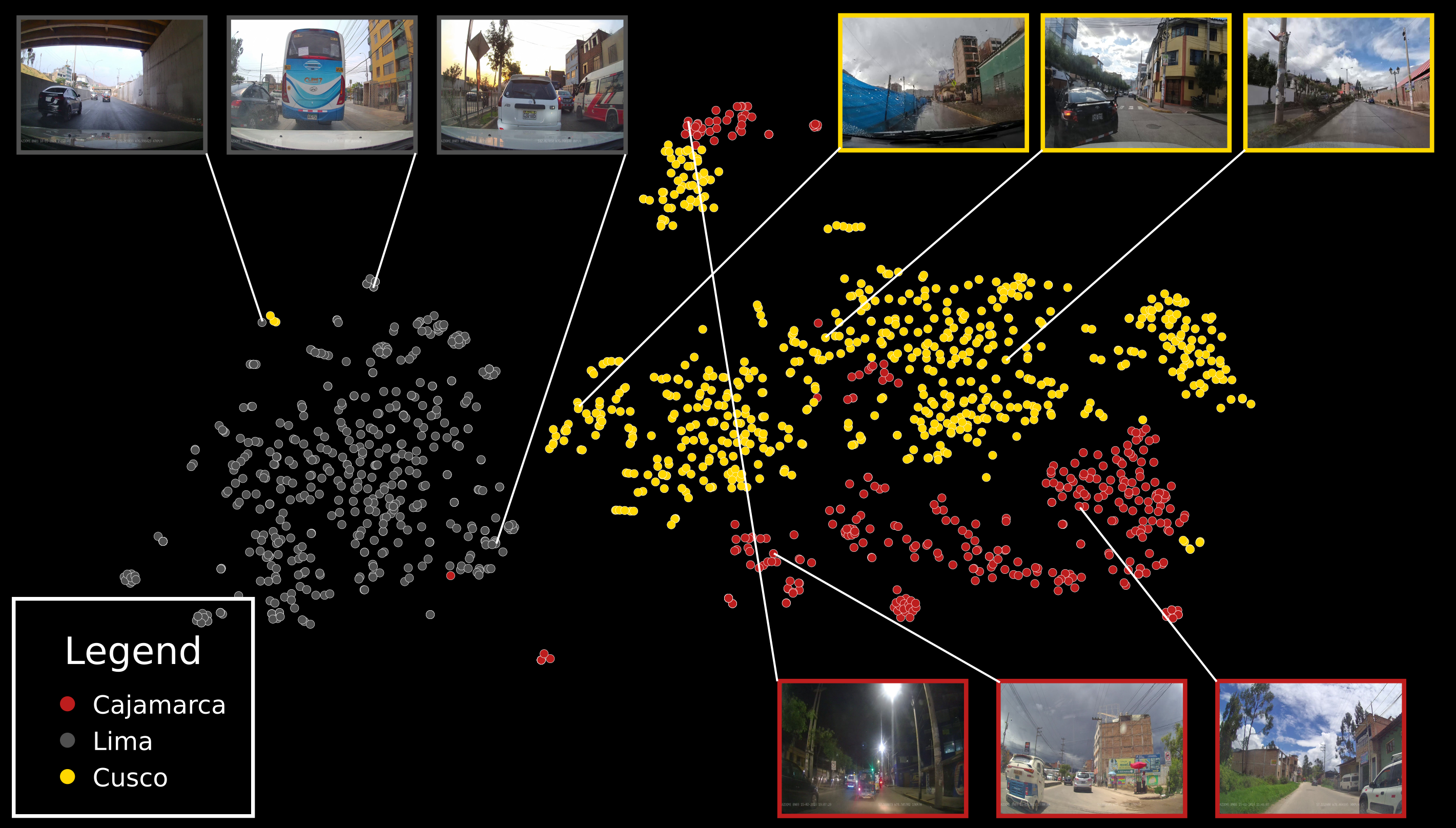
Our inaugural dataset spans 1,441 sampled frames across Lima, Cusco and Cajamarca. Collected during peak traffic hours (2–6 pm), it captures the full range of Peruvian driving conditions — from crowded city centres to rural mountain roads.
Beyond standard cars and buses, our dataset includes tuk-tuks, ice cream carts, motorbikes with front baskets, improvised speed bumps, and pedestrian crowds. This long tail of objects is exactly what makes autonomous driving hard — and exactly what our data captures.

Processing thousands of hours of raw dashcam footage into clean, labeled, versioned training datasets is a compute-intensive operation. NVIDIA GPUs compress what would take weeks into hours.
NVIDIA NVDEC hardware decoders process raw H.264/H.265 footage at 10× the speed of CPU-based pipelines, enabling real-time ingestion of the entire taxi fleet's daily recordings.
Each ingested frame is passed through GPU-batched YOLO and Detectron2 pipelines to generate candidate annotations, accelerating the human-in-the-loop labeling workflow.
GPU-accelerated NeRF and depth-estimation models reconstruct 3D driving scenes from 2D dashcam footage, creating photorealistic simulation environments for model testing.
