Vision Language Action
A unified end-to-end model that sees the road, understands language, and acts — trained on the world's most challenging driving environments to generalise anywhere on Earth.
A unified end-to-end model that sees the road, understands language, and acts — trained on the world's most challenging driving environments to generalise anywhere on Earth.
From raw camera pixels to steering commands — no hand-crafted rules, no modular pipelines. One unified model drives.
Natural language instructions are fused directly into the action policy, enabling passengers to direct the vehicle conversationally.
Built on publicly available VLA checkpoints, reducing training CapEx by an order of magnitude versus proprietary model development.
New dashcam footage from our global taxi network flows into nightly fine-tuning cycles, keeping the model sharp on emerging edge cases.

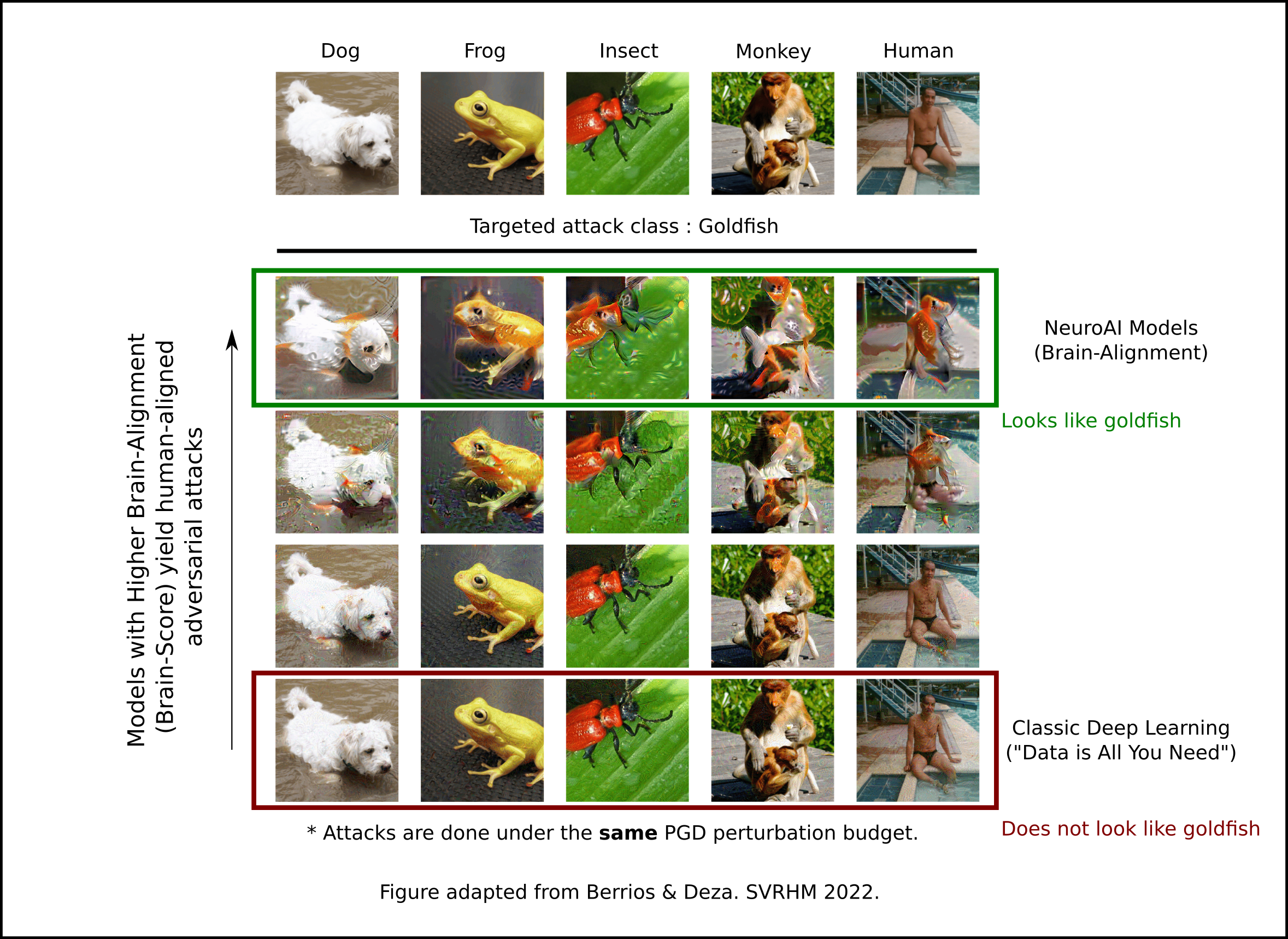
Unlike purely data-hungry deep learning models, our VLA incorporates NeuroAI principles — representations shaped by human visual cortex research. This means the model makes perceptual errors that are interpretable and predictable, not random, dramatically improving safety in unpredictable urban environments.
Trained on Lima's chaotic intersections, Cusco's mountain roads, and Cajamarca's rural routes, our VLA has seen conditions that break every other model. Aggressive lane changes, unmapped speed bumps, and tuk-tuks are standard training fare — not edge cases.
Every VLA training run, every inference call, and every real-time decision aboard our vehicles is accelerated by NVIDIA's GPU platform — the same hardware stack that underlies the world's most capable AI systems.
Multi-node H100 NVLink clusters reduce full VLA fine-tuning runs from weeks to hours, enabling rapid iteration on new regional driving data.
NVIDIA TensorRT optimizes the deployed VLA to run at 30 fps on in-vehicle GPUs, meeting the strict latency requirements of autonomous navigation.
Raw dashcam video from thousands of taxis is decoded, augmented, and tokenized using CUDA kernels, feeding a continuous stream of fresh training examples to the model.
